
YOLOv8文件分析

文件分析
一、本文介绍
本文给大家带来的是YOLOv8项目的解读,之前给大家分析了YOLOv8的项目文件分析,这一篇文章给大家带来的是模型训练从我们的yaml文件定义到模型的定义部分的讲解,我们一般只知道如何去训练模型,和配置yaml文件,但是对于yaml文件是如何输入到模型里,模型如何将yaml文件解析出来的确是不知道的,本文的内容接上一篇的代码逐行解析(一) 项目目录分析,本文对于小白来说非常友好,非常推荐大家进行阅读,深度的了解模型的工作原理已经流程,下面我们从yaml文件来讲解。
本文的讲解全部在代码的对应位置进行注释介绍非常详细,以下为部分内容的截图。
二、yaml文件的定义
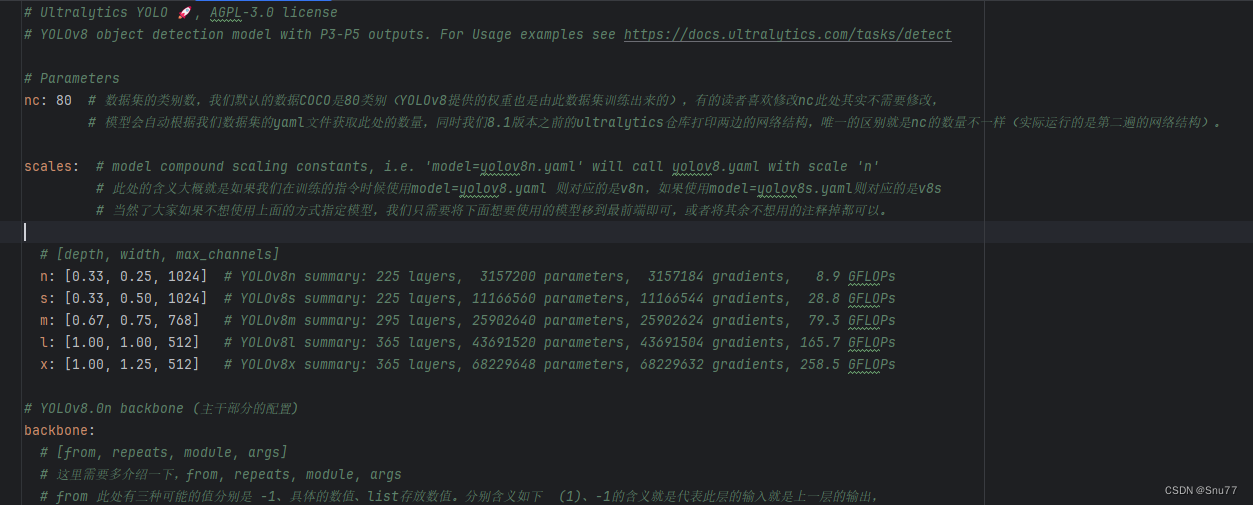
我们训练模型的第一步是需要配置yaml文件,我们的讲解第一步也从yaml文件来开始讲解,YOLOv8的yaml文件存放在我们的如下目录内’ultralytics/cfg/models/v8’,在其中我们可以定义各种模型配置的文件组合不同的模块,我们拿最基础的YOLOv8yaml文件来讲解一下。
注释部分的内容我就不介绍了,我只介绍一下其中有用的部分,我已经在代码中对应的位置注释上了解释,大家可以看这样看起来也直观一些。
1 | # Ultralytics YOLO 🚀, AGPL-3.0 license |
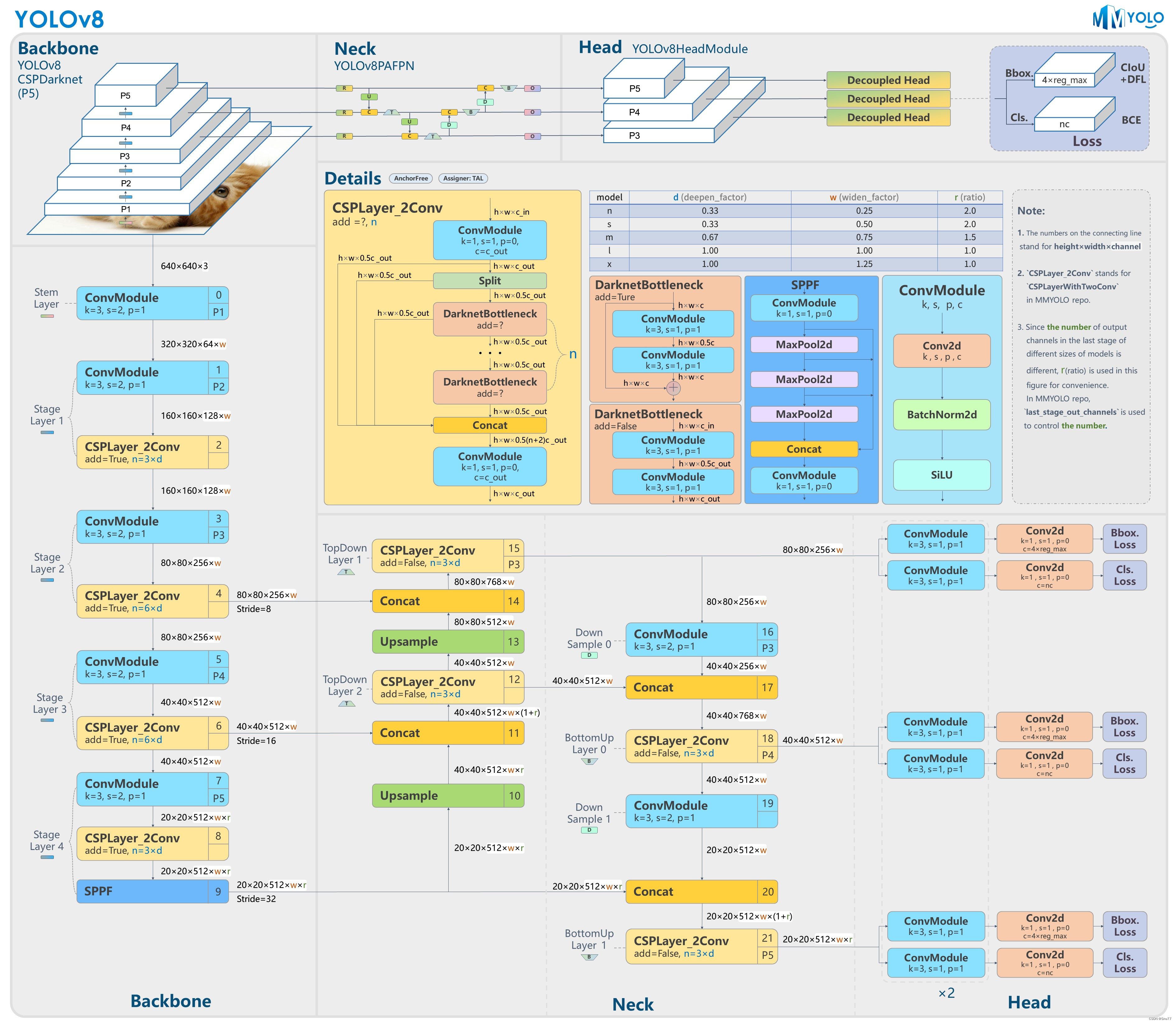
其中的Conv和C2f的结构我就不过多解释了,网上教程已经很多了,其中详细的结构在下图中都能够看到。
三、yaml文件的输入
上面我们解释了yaml文件中的参数含义,然后提供了一个结构图(其中能够获取到每个模块的详细结构,该结构图来源于官方)。然后我们下一步介绍当定义好了一个ymal文件其是如何传入到模型的内部的,模型的开始在哪里。
3.1 模型的定义
我们通过命令行的命令或者创建py文件运行模型之后,模型最开始的工作是模型的定义操作。模型存放于文件’ultralytics/engine/model.py’内部,首先需要通过’__init__‘来定义模型的一些变量。
此处我将模型的定义部分的代码解释了一下,大家有兴趣的可以和自己的文件对比着看。
1 | class Model(nn.Module): |
3.2 模型的训练
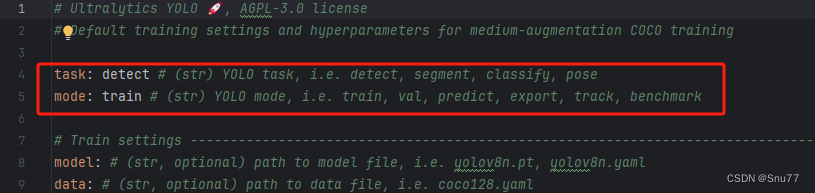
我们上面讲完了模型的定义,然后模型就会根据你指定的参数来进行调用对应的函数,比如我这里指定的是detect,和train,如下图所示,然后模型就会根据指定的参数进行对应任务的训练。
图片来源于文件’ultralytics/cfg/default.yaml’ 截图。
此处执行的是ultralytics/engine/model.py’文件中class Model(nn.Module):类别的def train(self, trainer=None, **kwargs):函数,具体的解释我已经在代码中标记了。
1 | def train(self, trainer=None, **kwargs): |
3.3 模型的网络结构打印
第三步比较重要的就是来到了’ultralytics/nn/tasks.py’(就是我们改进模型时候的那个文件)文化内的class DetectionModel(BaseModel):类中进行初始化和模型的定义工作。
这里涉及到了模型的定义和校验工作(在模型的正式开始训练之前检测模型是否能够运行的工作!)。
1 | class DetectionModel(BaseModel): |
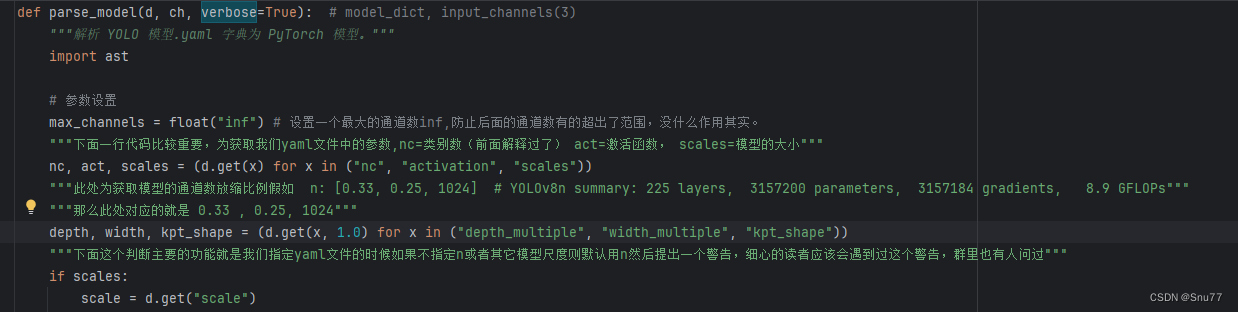
3.4 parse_model的解析
这里涉及到yaml文件中模块的定义和,通道数放缩的地方,此处大家可以仔细看看比较重要涉及到模块的改动。
1 | def parse_model(d, ch, verbose=True): # model_dict, input_channels(3) |
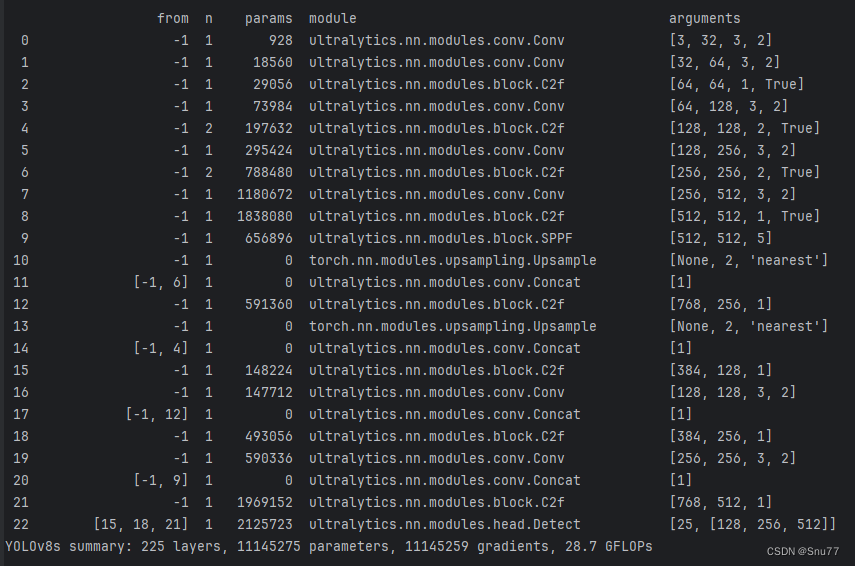
四、模型的结构打印
经过上面的分析之后,我们就会打印了模型的结构,图片如下所示,然后到此本篇文章的分析就到这里了,剩下的下一篇文章讲解。
(需要注意的是上面的讲解整体是按照顺序但是是以递归的形式介绍,比如3.2是3.1当中的某一行代码的功能而不是结束之后才允许的3.2,而是3.1运行的过程中运行了3.2。)
- 标题: YOLOv8文件分析
- 作者: Louaq
- 创建于 : 2024-08-19 12:00:00
- 更新于 : 2024-10-01 08:20:10
- 链接: https://github.com/Louaq/2024/08/19/article_4/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。